Étant en train de faire de nombreux changements dans mon homelab, tant du côté de l’infrastructure que des outils, en passant par la sauvegarde. Je m’attarde aujourd’hui sur un point annexe rencontré lors de la migration de mon instance FreshRSS.
Bien occupé par d’autres préoccupations ces dernières années, la mise à jour de certains services commençaient à prendre du retard. En migrant FreshRSS, j’en ai profité pour mettre l’outil à jour et partir sur la dernière version en date. Rien à redire, l’outil fonctionne toujours aussi bien, fait ce qu’on lui demande et réponds à mes besoins pour le suivi de flux RSS. Par contre, un petit changement dans l’UX/UI m’a très vite contrarié.
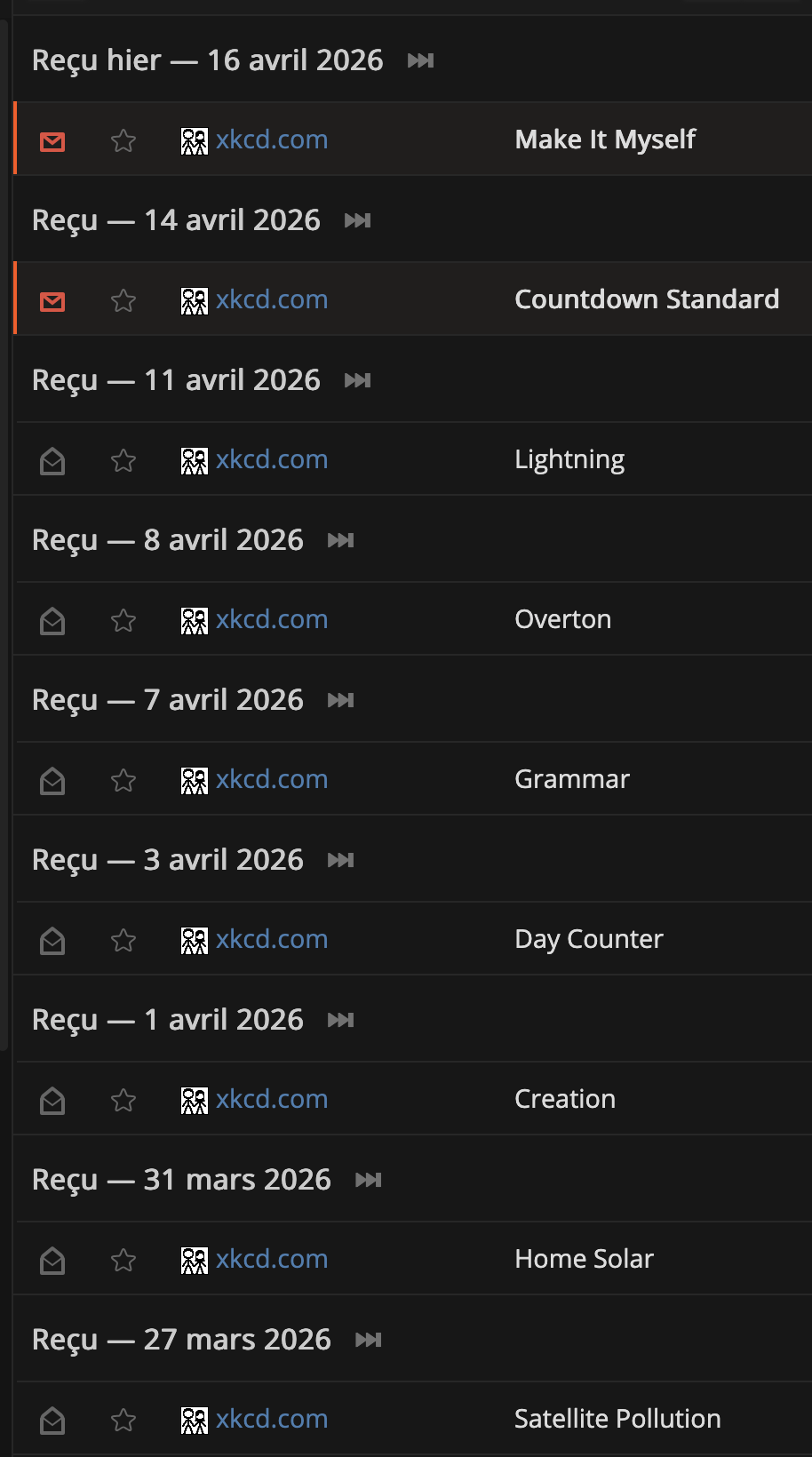
Désormais, FreshRSS organise toutes les entrées par date et regroupe donc les flux par jour, avec un entête de séparation. Si ce changement ne se sent pas particulièrement en consultant le flux principal contenant les entrées de tous mes flux RSS, le résultat est plutôt perturbant lorsqu’on consulte le détail d’un flux RSS en particulier. La page devient alors une alternance entre entête de date et entrée de flux. La majeure partie des flux que je consulte publient très rarement plus d’une entrée par jour. Ma page se remplie d’entête de date qui constitue la moitié du contenu de la page et dont je n’ai pas l’utilité.
Bref, direction GitHub pour confirmer qu’un changement a eu lieu et savoir si un contournement ou une option de configuration existe. Bingo, deux issues existent:
Avant de passer à la solution que j’ai mise en place pour arriver à quelque chose de satisfaisant, voici la situation irritante en images.
Avant, un flux n’avait que trois entêtes: « Today », « Yesterday » et « Before yesterday ».
Et désormais, avec une entête par jour, on obtient quelque chose comme cela:
Quelle est donc la solution, me direz-vous ?
Les discussions sur GitHub proposent d’activer l’extension « User CSS » et d’ajouter la règle suivante:
.transition {
display: none;
}Ce qui a pour effet de faire disparaître toutes les entêtes. C’est mieux, mais insuffisant à mon goût. J’ai vraiment l’impression de perdre en lisibilité, car je ne peux plus distinguer les entrées récentes (les deux derniers jours) des entrées plus anciennes. En continuant d’expérimenter avec des règles CSS plus complexes pour tenter d’arriver à une présentation me convenant, j’aperçois un bouton permettant d’activer l’extension « User JS ». Ayant passé de nombreuses années à expérimenter et construire des solutions avec du JS, un début d’idée commence à germer dans mon esprit. Avec l’aide d’un MutationObserver pour intercepter les changements du DOM, je devrais être en mesure de détecter l’ajout des entêtes dans le DOM et de ne garder que les trois premières, retrouvant ainsi une présentation proche de la version historique à laquelle je suis habitué.
Après quelques itérations, voici donc le code que j’utilise:
const labels = ['Today', 'Yesterday', 'Before yesterday'];
let transitionCount = 0;
function processTransition(el) {
const i = transitionCount++;
if (i >= 3) {
el.style.display = 'none';
} else {
const link = el.querySelector('.transition-value a:first-child');
if (link) {
link.textContent = labels[i];
}
}
}
const main = document.querySelector('main');
main.querySelectorAll('.transition').forEach(processTransition);
const observer = new MutationObserver((mutations) => {
for (const mutation of mutations) {
for (const node of mutation.addedNodes) {
if (node.nodeType !== 1) {
continue;
}
if (node.classList?.contains('transition')) {
processTransition(node);
} else {
node.querySelectorAll?.('.transition').forEach(processTransition);
}
}
}
});
observer.observe(main, { childList: true, subtree: true });Ce qui nous donne le résultat suivant:
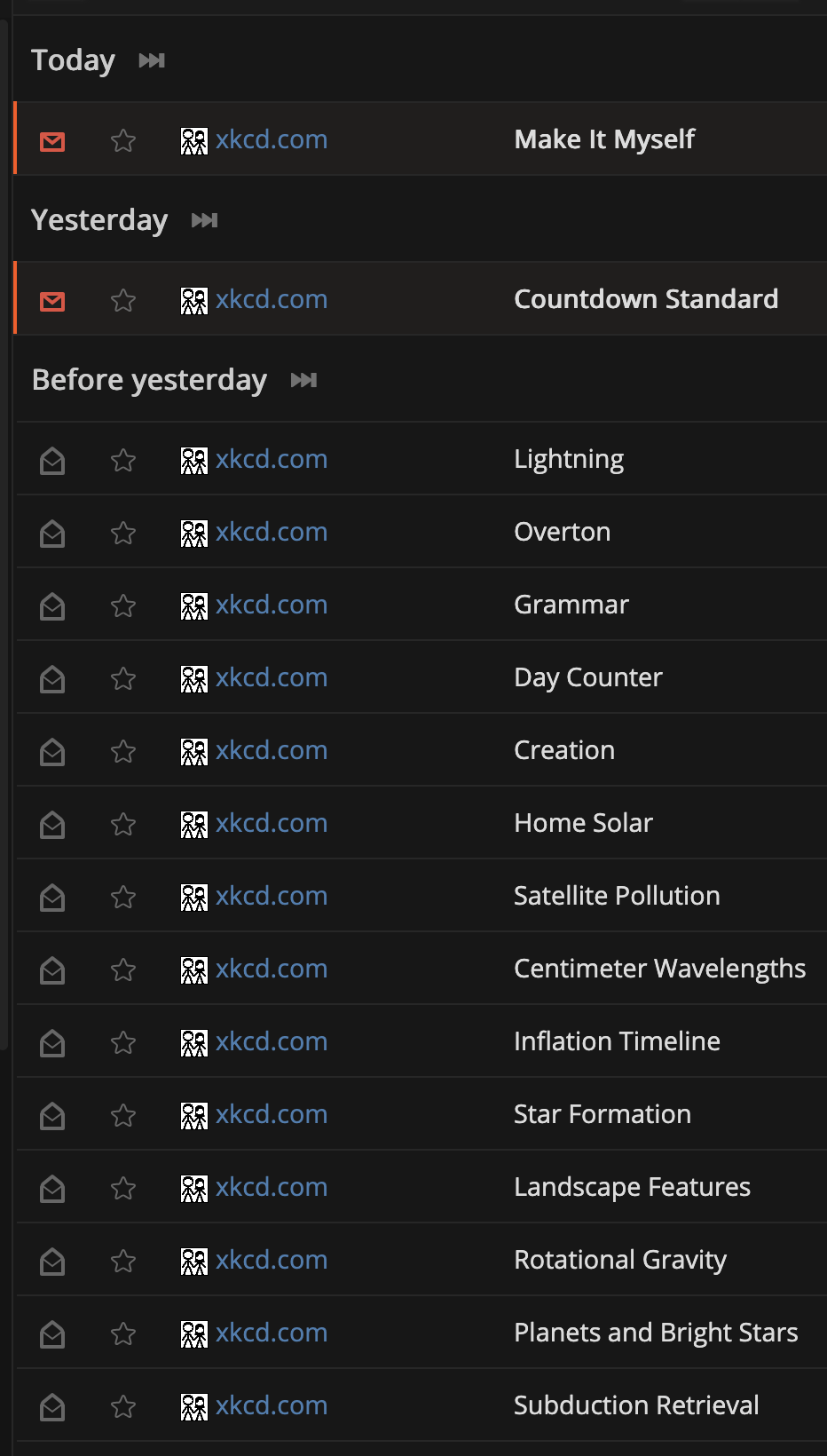
On constate immédiatement que l’information est bien plus condensée et qu’il y a, à mon goût, moins d’espace perdu. Je me rends compte en écrivant ces lignes, que les labels que j’utilise ne correspondent toutefois plus vraiment. En effet, dans mon exemple avec le flux xkcd, les deux entrées les plus récentes ont été reçues le lendemain de leur publication, mais à deux jours d’intervalles. Mon affichage « Aujourd’hui » (« Today ») et « Hier » (« Yesterday »), est donc inexacte, mais correspond en tout cas à un regroupement qui me convient. Après réflexion, je m’oriente donc vers un découpage « Latest », « Previous » et « Older ».
Pour avoir utilisé cette solution au quotidien depuis maintenant plusieurs semaines, je suis tout à fait satisfait du résultat. Bien sûr, il y a parfois quelques clignotements dans l’interface, le temps que le code s’exécute et que les entêtes soient cachées ou que leur titre change, mais rien qui ne soit gênant.