Dans l’article précédent, j’évoquais quelques étapes de préparation du NAS et l’installation d’OpenMediaVault. Une fois ces étapes effectuées, je me suis donc tourné vers la mise en place des disques durs de données.
J’ai décidé de commencer doucement et j’ai choisi deux disques Western Digital Red 1 To. Afin d’éviter d’avoir deux disques provenant d’un même lot et ainsi réduire les risques de défaillance simultanée, je me suis procuré les disques auprès de deux enseignes différentes. L’un en Allemagne chez MediaMarkt, l’autre chez Amazon.
Une fois les disques en ma possession, quelques coups de tournevis pour monter le support et je charge les disques dans le NAS éteint. Démarrage. Authentification. Arrivé sur l’interface du NAS, je vérifie les disques détectés par le système : j’en vois bien trois, mes deux disques de 1 To et le SSD. Pas de problème à priori. Je clique donc sur le menu gestion du RAID pour configurer un raid miroir sur les deux disques. Bouton créer; je complète la configuration du périphérique RAID, clique sur enregistrer, et là, c’est le drame.
Rien ne se produit… Je devrais avoir un état d’avancement de la construction du RAID, rien. Pourtant, après investigation, le RAID semble avoir été initialisé. Dans le doute, je redémarre le NAS… Le système boot, puis affiche des lignes d’erreurs, avant de continuer à démarrer. L’un des disques semble avoir des problèmes.
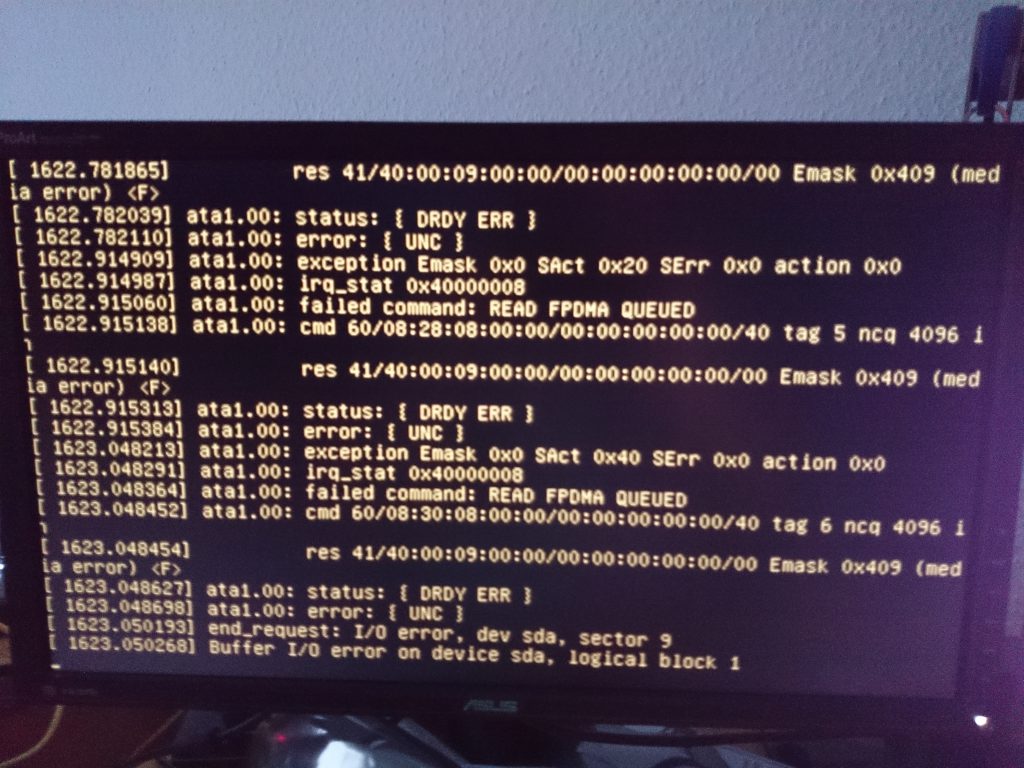
Je tente alors de diagnostiquer le problème. La question que je me pose est la suivante : « Mon disque est-il défectueux depuis son acquisition ou, une erreur lors de la création du RAID peut-elle avoir entraînée une corruption d’un secteur ? Bref, le problème est-il corrigeable ou non ? ». Pour essayer de répondre à ces interrogations, je vais exécuter des tests SMART pour tenter de déterminer précisément l’état du disque. Pour cela, je me tourne sous GNU/Linux vers Smartmontools avec la commande :
smartctl -i /dev/sdX
Je n’ai pas sauvegardé les résultats des différentes commandes. Globalement, ce que j’apprends et comprends dans les informations retenues, c’est que mon disque fonctionne (tourne), mais que le taux d’erreur est impressionnant et qu’il ne semble pas être en mesure de lire un seul secteur. Je tente donc de lancer des tests plus poussés, un long puis un cours en arrière plan :
smartctl -t short /dev/sdX
smartctl -t long /dev/sdX
Puis une heure plus tard, je regarde les résultats :
smartctl -a /dev/sdX
Pas de chance, les deux tests sont en erreur et n’ont pas réussi à finir. Pas beaucoup plus avancé, sinon que ça ne marche vraiment pas. En faisant des recherches sur le web pour essayer de comprendre, je tombe sur la question ATA drive is failing self-tests, but SMART health status is ‘PASSED’. What’s going on? soit en français, les tests sont en erreur, le status de santé du disque est « ok », que ce passe-t-il ? D’après ce qui est écrit en réponse, j’en déduis qu’écrire une donnée sur le disque pourrait forcer une réallocation de secteur endommagé s’il y en a un présent ou permettre d’écrire une donnée « cohérente ».
Mon disque ne contient pas de système de fichier, un certain nombre de solutions proposées tombent à l’eau. En dernier recours, je tente de réécrire des données aléatoires sur l’ensemble du disque avec :
dd if=/dev/urandom > /dev/sdX
Cela semble fonctionner, ça mouline, c’est long. Les tests ayant incriminé un secteur proche du début du disque, je coupe la commande à la moitié pour gagner du temps. Redémarrage, mais pas d’amélioration. À ce stade, j’en conclue que le disque est défectueux et qu’il va donc falloir tenter de le faire remplacer. Le disque concerné est celui en provenance d’Amazon. J’étudie leur politique de retour, ça semble plutôt facile et ils n’ont pas l’air de chipoter.
Avant de me résigner à renvoyer le disque, je décide de le tester une dernière fois avec les outils de tests du constructeur. Celui de Western Digital n’est disponible que sous Windows et le disque doit être monté en SATA; pas possible d’utiliser un connecteur USB, le disque n’est pas reconnu. Les résultats sont les suivants :
Western Digital Logo Test Option: QUICK TEST Model Number: WDC WD10EFRX-68FYTN0 Unit Serial Number: WD-WCC4J4VZKS2H Firmware Number: 82.00A82 Capacity: 1000.20 GB SMART Status: PASS Test Result: FAIL Test Error Code: 06-Quick Test on drive 4 did not complete! Status code = 07 (Failed read test element), Failure Checkpoint = 97 (Unknown Test) SMART self-test did not complete on drive 4! Test Time: 17:54:31, August 01, 2016
Ce n’est pas mieux. Le contrôleur RAID du NAS, les outils de diagnostic Western Digital, Smartmontools, tous indiquent que le disque n’a jamais fonctionné correctement. Je renvoie donc le disque et demande son remboursement. Quitte à devoir en obtenir un nouveau, je préfère qu’il n’arrive pas par transporteur et lui éviter les chocs. Je me tourne donc vers materiel.net et leur boutique proche de Strasbourg qui indique que le disque est en stock pour quelques euros de moins.
Bref, achat direct d’un nouveau disque dur le lendemain et montage dans le NAS, et cette fois ça y est, la construction du RAID démarre. Je retiendrai qu’acheter un disque dur par correspondance n’est pas une bonne idée, on peut avoir de la chance ou pas, mais il est probable que le disque aura subi de nombreux chocs durant le transport. J’ai voulu essayer, je suis fixé.
Les sources d’informations utilisées durant mes recherches :
https://www.thomas-krenn.com/en/wiki/SMART_tests_with_smartctl
http://www.linuxtechi.com/smartctl-monitoring-analysis-tool-hard-drive/
https://wiki.archlinux.org/index.php/Securely_wipe_disk#Non-random_data
https://www.smartmontools.org/wiki/FAQ#ATAdriveisfailingself-testsbutSMARThealthstatusisPASSED.Whatsgoingon
https://www.smartmontools.org/browser/trunk/www/badblockhowto.xml
https://wiki.archlinux.org/index.php/RAID
https://wiki.archlinux.org/index.php/S.M.A.R.T.
https://unix.stackexchange.com/questions/113737/does-my-hard-drive-have-bad-sectors-or-not